탐욕 알고리즘이 매 순간 최적의 선택을 찾는 방식이라면, Dynamic Programming은 모든 경우의 수를 조합해 최적의 해법을 찾는 방식입니다.
Dynamic Programming의 원리
주어진 문제를 여러 개의 하위 문제로 나누어 풀고, 하위 문제들의 해결 방법을 결합하여 최종 문제를 해결하는 문제 해결 방식입니다.
하위 문제를 계산한 뒤 그 해결책을 저장하고, 나중에 동일한 하위 문제를 만날 경우 저장된 해결책을 적용해 계산 횟수를 줄입니다.
조건
- 큰 문제를 작은 문제로 나눌 수 있고, 이 작은 문제가 중복해서 발견된다. (Overlapping Sub-problems)
- 작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 같다. 즉, 작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다. (Optimal Substructure)
첫 번째 조건
큰 문제를 작은 문제로 나눌 수 있고, 이 작은 문제가 중복해서 발견된다 (Overlapping Sub-problems) 는
큰 문제로부터 나누어진 작은 문제는 큰 문제를 해결할 때 여러 번 반복해서 사용될 수 있어야 한다 는 말과 같습니다.
피보나치 수열은 첫째와 둘째 항이 1이며, 그 뒤의 모든 항은 바로 앞 두 항의 합과 같은 수열입니다. 피보나치 수열을 재귀 함수로 구현해 보면, 다음과 같이 작성할 수 있습니다.
function fib(n) {
if(n <= 2) return 1;
return fib(n - 1) + fib(n - 2);
}
// 1, 1, 2, 3, 5, 8...
fib(7) = fib(6) + fib(5)
fib(7) = (fib(5) + fib(4)) + fib(5) // fib(6) = fib(5) + fib(4)
fib(7) = ((fib(4) + fib(3)) + fib(4)) + (fib(4) + fib(3)) // fib(5) = fib(4) + fib(3) .....
fib(5) 는 두 번, fib(4) 는 세 번, fib(3) 은 다섯 번의 동일한 계산을 반복합니다.
이렇게 작은 문제의 결과를 큰 문제를 해결하기 위해 여러 번 반복하여 사용할 수 있을 때, 부분 문제의 반복(Overlapping Sub-problems)이라는 조건을 만족한다
주의해야할 점
주어진 문제를 단순히 반복 계산하여 해결하는 것이 아니라, 작은 문제의 결과가 큰 문제를 해결하는 데에 여러 번 사용될 수 있어야 합니다.
두 번째 조건
작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다(Optimal Substructure).
즉 조건에서 말하는 정답은 최적의 해결 방법(Optimal solution)을 의미한다.
주어진 문제에 대한 최적의 해법을 구할 때, 주어진 문제의 작은 문제들의 최적의 해법(Optimal solution of Sub-problems)을 찾아야 합니다.
그리고 작은 문제들의 최적의 해법을 결합하면, 결국 전체 문제의 최적의 해법(Optimal solution)을 구할 수 있습니다.
최단 경로를 구하는 경로
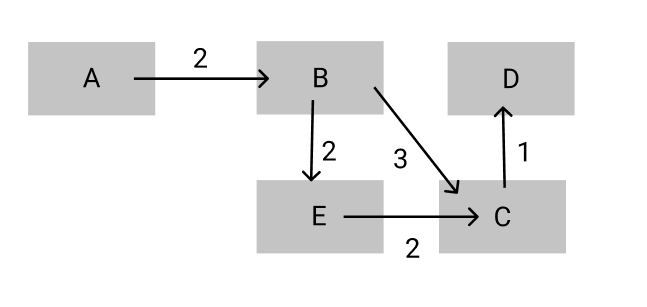
A에서 D로 가는 최단 경로는 A → B → C → D 입니다.
그렇다면 A에서 C로 가는 최단 경로는 어떨까요? A → B → E → C가 아닌 A → B → C 입니다.
마지막으로 A에서 B로 가는 최단 경로는? 당연히 A → B 입니다.
정리해보면 A에서 D로 가는 최단 경로는 그것의 작은 문제인 A에서 C로 가는 최단 경로, 그리고 한번 더 작은 문제인 A에서 B로 가는 최단 경로의 파악할 수 있습니다.
작은 문제의 최적 해법을 결합하여 최종 문제의 최적 해법을 구할 수 있어야 합니다.
Memoization
Memoization의 정의는 컴퓨터 프로그램이 동일한 계산을 반복해야 할 때, 이전에 계산한 값을 메모리에 저장함으로써 동일한 계산의 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술 입니다.
function fibMemo(n, memo = []) {
// 이미 해결한 하위 문제인지 찾아본다
if(memo[n] !== undefined) return memo[n];
if(n <= 2) return 1;
// 없다면 재귀로 결괏값을 도출하여 res 에 할당
let res = fibMemo(n-1, memo) + fibMemo(n-2, memo); // 추후 동일한 문제를 만났을 때 사용하기 위해 리턴 전에 memo 에 저장
memo[n] = res;
return res;
}
- 먼저 fibMemo 함수의 파라미터로 n 과 빈 배열을 전달합니다. 이 빈 배열은 하위 문제의 결괏값을 저장하는 데에 사용합니다.
- memo 라는 빈 배열의 n번째 인덱스가 undefined 이 아니라면, 다시 말해 n 번째 인덱스에 어떤 값이 저장되어 있다면, 저장되어 있는 값을 그대로 사용합니다.
- undefined라면, 즉 처음 계산하는 수라면 fibMemo(n-1, memo) + fibMemo(n-2, memo)를 이용하여 값을 계산하고, 그 결괏값을 res 라는 변수에 할당합니다.
- 마지막으로 res 를 리턴하기 전에 memo 의 n 번째 인덱스에 res 값을 저장합니다. 이렇게 하면 (n+1)번째의 값을 구하고 싶을 때, n번째 값을 memo 에서 확인해 사용할 수 있습니다.
Tabulation
하위 문제의 결괏값을 배열에 저장하고, 필요할 때 조회하여 사용하는 것은 재귀 함수를 이용한 방법과 같습니다.
그러나 재귀 함수를 이용한 방법이 문제를 해결하기 위해 큰 문제부터 시작하여 작은 문제로 옮아가며 문제를 해결하였다면, 반복문을 이용한 방법은 작은 문제에서부터 시작하여 큰 문제를 해결해 나가는 방법입니다.
function fibTab(n) {
if(n <= 2) return 1;
let fibNum = [0, 1, 1];
// n 이 1 & 2일 때의 값을 미리 배열에 저장해 놓는다
for(let i = 3; i <= n; i++) {
fibNum[i] = fibNum[i-1] + fibNum[i-2];
// n >= 3 부터는 앞서 배열에 저장해 놓은 값들을 이용하여
// n번째 피보나치 수를 구한 뒤 배열에 저장 후 리턴한다
}
return fibNum[n];
}
- Top-down과 Bottom-up의 소요 시간을 비교하였을 때 결과에 어떤 차이가 있고, 그 원인은 무엇이었을까요?
- Tabulation(Bottom-up) runtime: 0.10000000149011612ms
- Memoization runtime: 0.09999999776482582ms
- 다이내믹 프로그래밍과 탐욕 알고리즘은 각각 어떤 경우에 사용하기 적합한 알고리즘일까요?
'code 알고리즘 > 그리디 알고리즘(Greedy Algorithm)' 카테고리의 다른 글
| 그리디 알고리즘 (0) | 2021.11.09 |
|---|